Estadística: medidas de tendencia y dispersión en datos agrupados
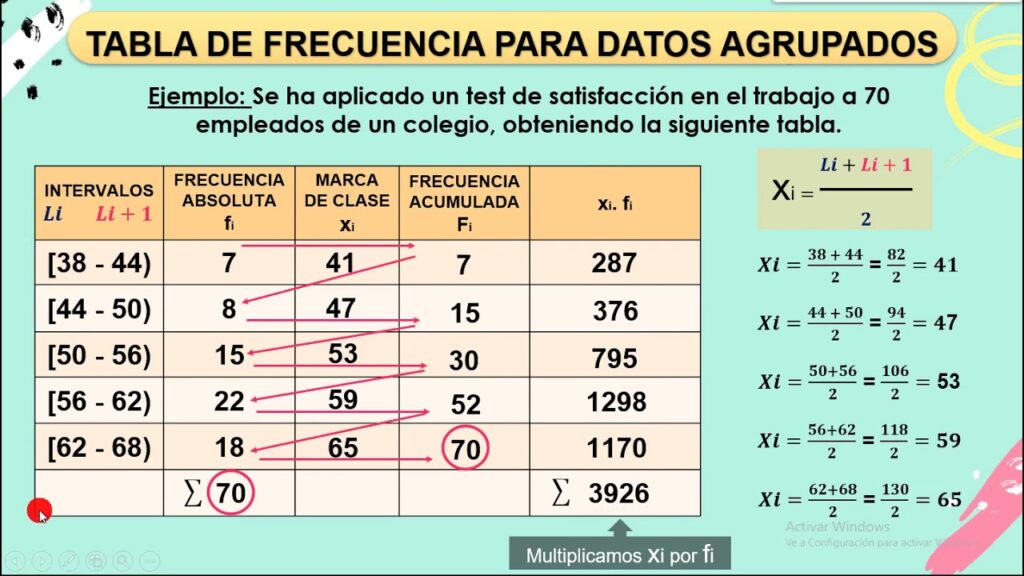
Si estás familiarizado con la estadística, probablemente hayas oído hablar de las medidas de tendencia central y de dispersión. Estas medidas son herramientas extremadamente útiles para analizar datos y obtener información valiosa a partir de ellos. Pero, ¿cómo se aplican estas medidas a los datos agrupados? En este artículo, vamos a profundizar en medidas de tendencia y dispersión en datos agrupados, ¡así que prepárate para sumergirte en el fascinante mundo de la estadística!
- ¿Qué son los datos agrupados?
- Medidas de tendencia central en datos agrupados
- Medidas de dispersión en datos agrupados
- Conclusión
- Preguntas frecuentes
- 1. ¿Por qué es importante utilizar medidas de tendencia central y de dispersión?
- 2. ¿Cuál es la diferencia entre datos agrupados y datos sin agrupar?
- 3. ¿Por qué es importante entender la diferencia entre los datos agrupados y los datos sin agrupar?
- 4. ¿Cómo se encuentran la mediana y la moda en los datos agrupados?
¿Qué son los datos agrupados?
Antes de adentrarnos en las medidas de tendencia y dispersión en datos agrupados, es importante entender qué son los datos agrupados. En estadística, los datos se dividen en dos categorías principales: datos agrupados y datos sin agrupar.
Los datos sin agrupar son simplemente una lista de números, sin ningún tipo de agrupamiento. Por ejemplo, una lista de las edades de los estudiantes en una clase sería un ejemplo de datos sin agrupar.
Por otro lado, los datos agrupados se organizan en categorías o intervalos. Por ejemplo, en lugar de tener una lista de las edades de los estudiantes, podríamos tener una lista de cuántos estudiantes tienen entre 10 y 15 años, cuántos tienen entre 15 y 20 años, y así sucesivamente.
Medidas de tendencia central en datos agrupados
Las medidas de tendencia central son valores que representan el centro de un conjunto de datos. Hay tres medidas de tendencia central comunes: la media, la mediana y la moda.
La media es simplemente la suma de todos los valores divididos por el número total de valores. Por ejemplo, si tenemos una lista de números sin agrupar, podemos encontrar la media sumando todos los valores y dividiéndolos por el número total de valores.
Sin embargo, en los datos agrupados, no podemos simplemente sumar todos los valores, ya que los datos están en intervalos. En su lugar, debemos utilizar una fórmula ligeramente diferente para encontrar la media. La fórmula es la siguiente:
$$bar{x} = frac{sum_{i=1}^k m_i f_i}{n}$$
Donde $bar{x}$ es la media, $m_i$ es el punto medio del intervalo $i$, $f_i$ es la frecuencia del intervalo $i$ y $n$ es el número total de datos.
La mediana es el valor que se encuentra en el centro de un conjunto de datos cuando se ordenan de menor a mayor. En los datos agrupados, debemos encontrar el intervalo que contiene la mediana y luego utilizar una fórmula para encontrar su valor aproximado. La fórmula es la siguiente:
$$Me = L_i + frac{frac{n}{2} - F_{i-1}}{f_i} cdot c$$
Donde $Me$ es la mediana, $L_i$ es el límite inferior del intervalo que contiene la mediana, $F_{i-1}$ es la frecuencia acumulada del intervalo anterior, $f_i$ es la frecuencia del intervalo que contiene la mediana y $c$ es la amplitud del intervalo.
La moda es el valor que aparece con mayor frecuencia en un conjunto de datos. En los datos agrupados, la moda se encuentra utilizando la fórmula:
$$Mo = L_i + frac{f_i - f_{i-1}}{2f_i - f_{i-1} - f_{i+1}} cdot c$$
Donde $Mo$ es la moda, $L_i$ es el límite inferior del intervalo que contiene la moda, $f_i$ es la frecuencia del intervalo que contiene la moda, $f_{i-1}$ es la frecuencia del intervalo anterior y $f_{i+1}$ es la frecuencia del intervalo siguiente.
Medidas de dispersión en datos agrupados
Las medidas de dispersión son valores que indican cómo se distribuyen los datos alrededor de la media. Hay tres medidas de dispersión comunes: el rango, la varianza y la desviación estándar.
El rango es simplemente la diferencia entre el valor más alto y el valor más bajo. En los datos agrupados, debemos encontrar el intervalo que contiene el valor más alto y el valor más bajo y utilizar una fórmula para encontrar su valor aproximado. La fórmula es la siguiente:
$$R = L_k - L_1$$
Donde $R$ es el rango, $L_k$ es el límite superior del último intervalo y $L_1$ es el límite inferior del primer intervalo.
La varianza es una medida de cuánto varían los datos alrededor de la media. La fórmula para encontrar la varianza en los datos agrupados es la siguiente:
$$s^2 = frac{sum_{i=1}^k (m_i - bar{x})^2f_i}{n-1}$$
Donde $s^2$ es la varianza, $m_i$ es el punto medio del intervalo $i$, $bar{x}$ es la media, $f_i$ es la frecuencia del intervalo $i$ y $n$ es el número total de datos.
La desviación estándar es simplemente la raíz cuadrada de la varianza. La fórmula para encontrar la desviación estándar en los datos agrupados es la siguiente:
$$s = sqrt{frac{sum_{i=1}^k (m_i - bar{x})^2f_i}{n-1}}$$
Donde $s$ es la desviación estándar.
Conclusión
Las medidas de tendencia central y de dispersión son herramientas extremadamente útiles para analizar datos y obtener información valiosa a partir de ellos. En los datos agrupados, debemos utilizar fórmulas ligeramente diferentes para encontrar estas medidas, pero el concepto básico sigue siendo el mismo. La próxima vez que te encuentres analizando datos agrupados, recuerda estas fórmulas y utiliza las medidas de tendencia central y de dispersión para obtener información valiosa.
Preguntas frecuentes
1. ¿Por qué es importante utilizar medidas de tendencia central y de dispersión?
Las medidas de tendencia central y de dispersión son importantes porque nos ayudan a entender cómo se distribuyen los datos alrededor de la media. Esto nos permite tomar decisiones informadas y hacer predicciones precisas basadas en los datos.
2. ¿Cuál es la diferencia entre datos agrupados y datos sin agrupar?
Los datos sin agrupar son simplemente una lista de números, sin ningún tipo de agrupamiento. Los datos agrupados se organizan en categorías o intervalos.
3. ¿Por qué es importante entender la diferencia entre los datos agrupados y los datos sin agrupar?
Es importante entender la diferencia entre los datos agrupados y los datos sin agrupar porque las fórmulas para encontrar las medidas de tendencia central y de dispersión son diferentes para cada tipo de datos.
4. ¿Cómo se encuentran la mediana y la moda en los datos agrupados?
Para encontrar la mediana y la moda en los datos agrupados, debemos utilizar fórmulas específicas que tienen en cuenta los intervalos y las
Deja una respuesta